Data Overview
MNIST ("Modified National Institute of Standards and Technology") dataset of computer vision. The MNIST database contains 60,000 training images and 10,000 testing images. Half of the training set and half of the test set were taken from NIST's training dataset, while the other half of the training set and the other half of the test set were taken from NIST's testing dataset.This project implements a beginner classification task on MNIST dataset with a Convolutional Neural Network(CNN) model.

This project will automatically dowload and process the MNIST dataset
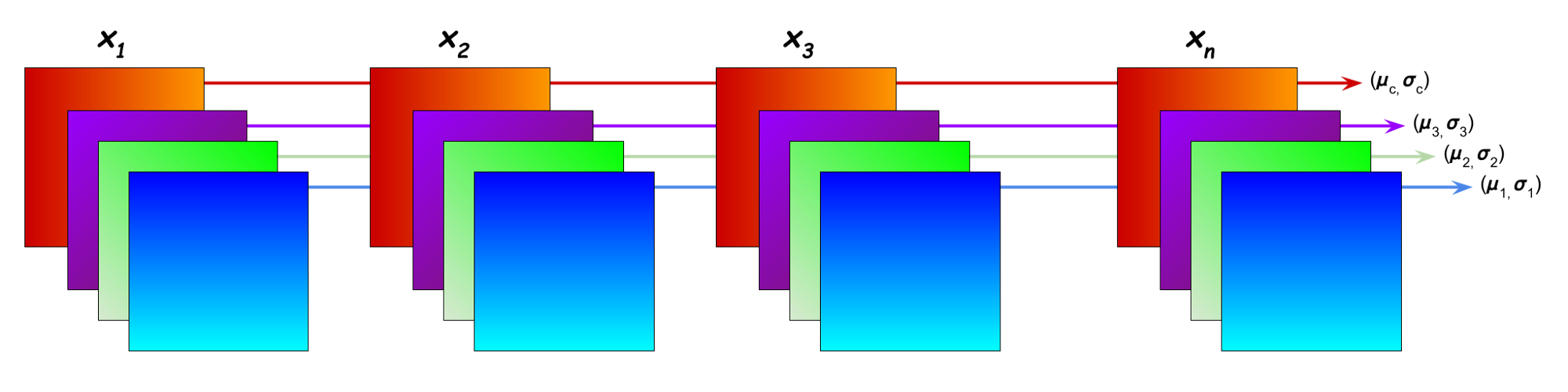
The basic idea behind these layers is to normalize the output of an activation layer to improve the convergence during training.
1 - BatchNorm:
Batch normalization works for each filter seperately using all the output of that filter
i.e Batch normalization is a method that normalizes activations in a network across the mini-batch of definite size
1 - Model Summary
Layer (type) Output Shape Param #
Conv2d-1 [-1, 8, 26, 26] 72
BatchNorm2d-2 [-1, 8, 26, 26] 16
Dropout-3 [-1, 8, 26, 26] 0
ReLU-4 [-1, 8, 26, 26] 0
Conv2d-5 [-1, 8, 24, 24] 576
BatchNorm2d-6 [-1, 8, 24, 24] 16
Dropout-7 [-1, 8, 24, 24] 0
ReLU-8 [-1, 8, 24, 24] 0
Conv2d-9 [-1, 8, 22, 22] 576
BatchNorm2d-10 [-1, 8, 22, 22] 16
Dropout-11 [-1, 8, 22, 22] 0
ReLU-12 [-1, 8, 22, 22] 0
MaxPool2d-13 [-1, 8, 11, 11] 0
Conv2d-14 [-1, 12, 9, 9] 864
BatchNorm2d-15 [-1, 12, 9, 9] 24
Dropout-16 [-1, 12, 9, 9] 0
ReLU-17 [-1, 12, 9, 9] 0
Conv2d-18 [-1, 14, 7, 7] 1,512
BatchNorm2d-19 [-1, 14, 7, 7] 28
Dropout-20 [-1, 14, 7, 7] 0
ReLU-21 [-1, 14, 7, 7] 0
Conv2d-22 [-1, 8, 7, 7] 112
BatchNorm2d-23 [-1, 8, 7, 7] 16
Dropout-24 [-1, 8, 7, 7] 0
ReLU-25 [-1, 8, 7, 7] 0
Conv2d-26 [-1, 26, 5, 5] 1,872
BatchNorm2d-27 [-1, 26, 5, 5] 52
Dropout-28 [-1, 26, 5, 5] 0
ReLU-29 [-1, 26, 5, 5] 0
Conv2d-30 [-1, 50, 5, 5] 1,300
BatchNorm2d-31 [-1, 50, 5, 5] 100
Dropout-32 [-1, 50, 5, 5] 0
ReLU-33 [-1, 50, 5, 5] 0
AvgPool2d-34 [-1, 50, 1, 1] 0
Conv2d-35 [-1, 10, 1, 1] 500
Total params: 7,652
Trainable params: 7,652
Non-trainable params: 0
Input size (MB): 0.00
Forward/backward pass size (MB): 0.55
Params size (MB): 0.03
Estimated Total Size (MB): 0.58
2 - Inference:
1 - Model Parameters is more and it's a heavy model .
2 - Model is over-fitting , we will make our model lighter in next step
2 - GroupNorm
Group Normalization(GN) divides the channels of your inputs into smaller sub groups and normalizes these values based on their mean and variance. Since GN works on a single example this technique is batchsize independent.
Layer (type) Output Shape Param #
Conv2d-1 [-1, 8, 26, 26] 72
GroupNorm-2 [-1, 8, 26, 26] 16
Dropout-3 [-1, 8, 26, 26] 0
ReLU-4 [-1, 8, 26, 26] 0
Conv2d-5 [-1, 8, 24, 24] 576
GroupNorm-6 [-1, 8, 24, 24] 16
Dropout-7 [-1, 8, 24, 24] 0
ReLU-8 [-1, 8, 24, 24] 0
Conv2d-9 [-1, 8, 22, 22] 576
GroupNorm-10 [-1, 8, 22, 22] 16
Dropout-11 [-1, 8, 22, 22] 0
ReLU-12 [-1, 8, 22, 22] 0
MaxPool2d-13 [-1, 8, 11, 11] 0
Conv2d-14 [-1, 12, 9, 9] 864
GroupNorm-15 [-1, 12, 9, 9] 24
Dropout-16 [-1, 12, 9, 9] 0
ReLU-17 [-1, 12, 9, 9] 0
Conv2d-18 [-1, 14, 7, 7] 1,512
GroupNorm-19 [-1, 14, 7, 7] 28
Dropout-20 [-1, 14, 7, 7] 0
ReLU-21 [-1, 14, 7, 7] 0
Conv2d-22 [-1, 8, 7, 7] 112
GroupNorm-23 [-1, 8, 7, 7] 16
Dropout-24 [-1, 8, 7, 7] 0
ReLU-25 [-1, 8, 7, 7] 0
Conv2d-26 [-1, 26, 5, 5] 1,872
GroupNorm-27 [-1, 26, 5, 5] 52
Dropout-28 [-1, 26, 5, 5] 0
ReLU-29 [-1, 26, 5, 5] 0
Conv2d-30 [-1, 50, 5, 5] 1,300
GroupNorm-31 [-1, 50, 5, 5] 100
Dropout-32 [-1, 50, 5, 5] 0
ReLU-33 [-1, 50, 5, 5] 0
AvgPool2d-34 [-1, 50, 1, 1] 0
Conv2d-35 [-1, 10, 1, 1] 500
Total params: 7,652
Trainable params: 7,652
Non-trainable params: 0
Input size (MB): 0.00
Forward/backward pass size (MB): 0.55
Params size (MB): 0.03
Estimated Total Size (MB): 0.58
2 - Inference:
1 - Model Parameters is more and it's a heavy model .
2 - Model is over-fitting , we will make our model lighter in next step
3 - LayerNorm:
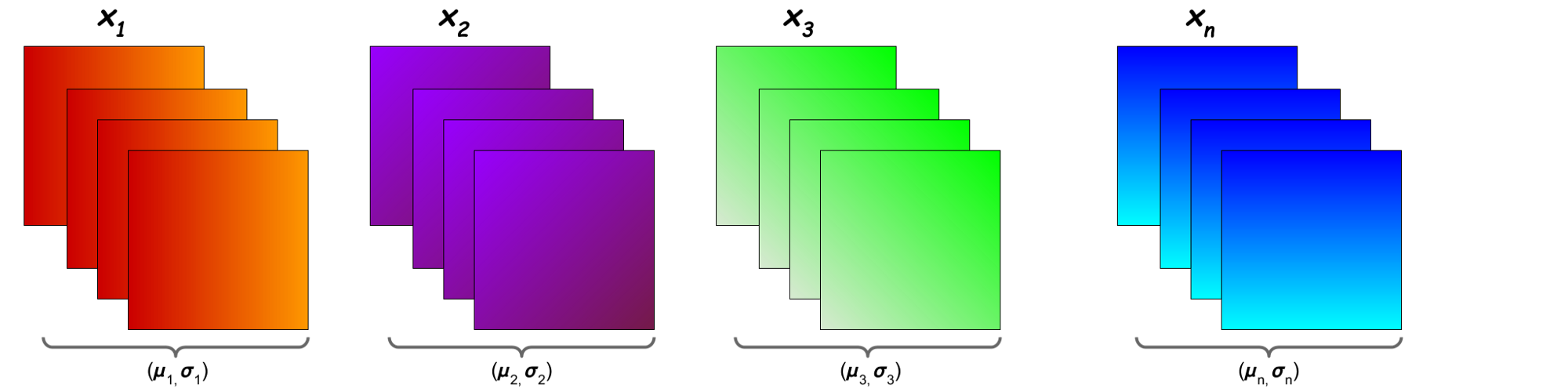
Layer Normalization work for each input seperately using output of all the filter for that input Layer Normalization is special case of group normalization where the group size is 1. The mean and standard deviation is calculated from all activations of a single sample.
1 - Model Summary
Layer (type) Output Shape Param #
Conv2d-1 [-1, 8, 26, 26] 72
LayerNorm-2 [-1, 8, 26, 26] 52
Dropout-3 [-1, 8, 26, 26] 0
ReLU-4 [-1, 8, 26, 26] 0
Conv2d-5 [-1, 8, 24, 24] 576
LayerNorm-6 [-1, 8, 24, 24] 48
Dropout-7 [-1, 8, 24, 24] 0
ReLU-8 [-1, 8, 24, 24] 0
Conv2d-9 [-1, 8, 22, 22] 576
LayerNorm-10 [-1, 8, 22, 22] 44
Dropout-11 [-1, 8, 22, 22] 0
ReLU-12 [-1, 8, 22, 22] 0
MaxPool2d-13 [-1, 8, 11, 11] 0
Conv2d-14 [-1, 12, 9, 9] 864
LayerNorm-15 [-1, 12, 9, 9] 18
Dropout-16 [-1, 12, 9, 9] 0
ReLU-17 [-1, 12, 9, 9] 0
Conv2d-18 [-1, 14, 7, 7] 1,512
LayerNorm-19 [-1, 14, 7, 7] 14
Dropout-20 [-1, 14, 7, 7] 0
ReLU-21 [-1, 14, 7, 7] 0
Conv2d-22 [-1, 8, 7, 7] 112
LayerNorm-23 [-1, 8, 7, 7] 14
Dropout-24 [-1, 8, 7, 7] 0
ReLU-25 [-1, 8, 7, 7] 0
Conv2d-26 [-1, 26, 5, 5] 1,872
LayerNorm-27 [-1, 26, 5, 5] 10
Dropout-28 [-1, 26, 5, 5] 0
ReLU-29 [-1, 26, 5, 5] 0
Conv2d-30 [-1, 50, 5, 5] 1,300
LayerNorm-31 [-1, 50, 5, 5] 10
Dropout-32 [-1, 50, 5, 5] 0
ReLU-33 [-1, 50, 5, 5] 0
AvgPool2d-34 [-1, 50, 1, 1] 0
Conv2d-35 [-1, 10, 1, 1] 500
Total params: 7,594
Trainable params: 7,594
Non-trainable params: 0
Input size (MB): 0.00
Forward/backward pass size (MB): 0.55
Params size (MB): 0.03
Estimated Total Size (MB): 0.58
2 - Inference:
1 - Model Parameters is more and it's a heavy model .
2 - Model is over-fitting , we will make our model lighter in next step
Client: Python, Pytorch, Numpy
Client: Python, Pytorch, Numpy