Multimodal Semantic Retrieval for Product Search (arXiv:2501.07365)
This repository contains an unofficial implementation of the approach described in "Multimodal Semantic Retrieval for Product Search" by Dong Liu & Esther Lopez Ramos (2024) / Amazon.
Repo contains end-to-end prototype for semantic product search leveraging both natural language and visual features, supporting text-to-product and image-to-product retrieval via a shared semantic embedding space.
The paper proposes several multimodal retrieval architectures including 3-tower and 4-tower designs, where independent encoders process product images and text before fusion.
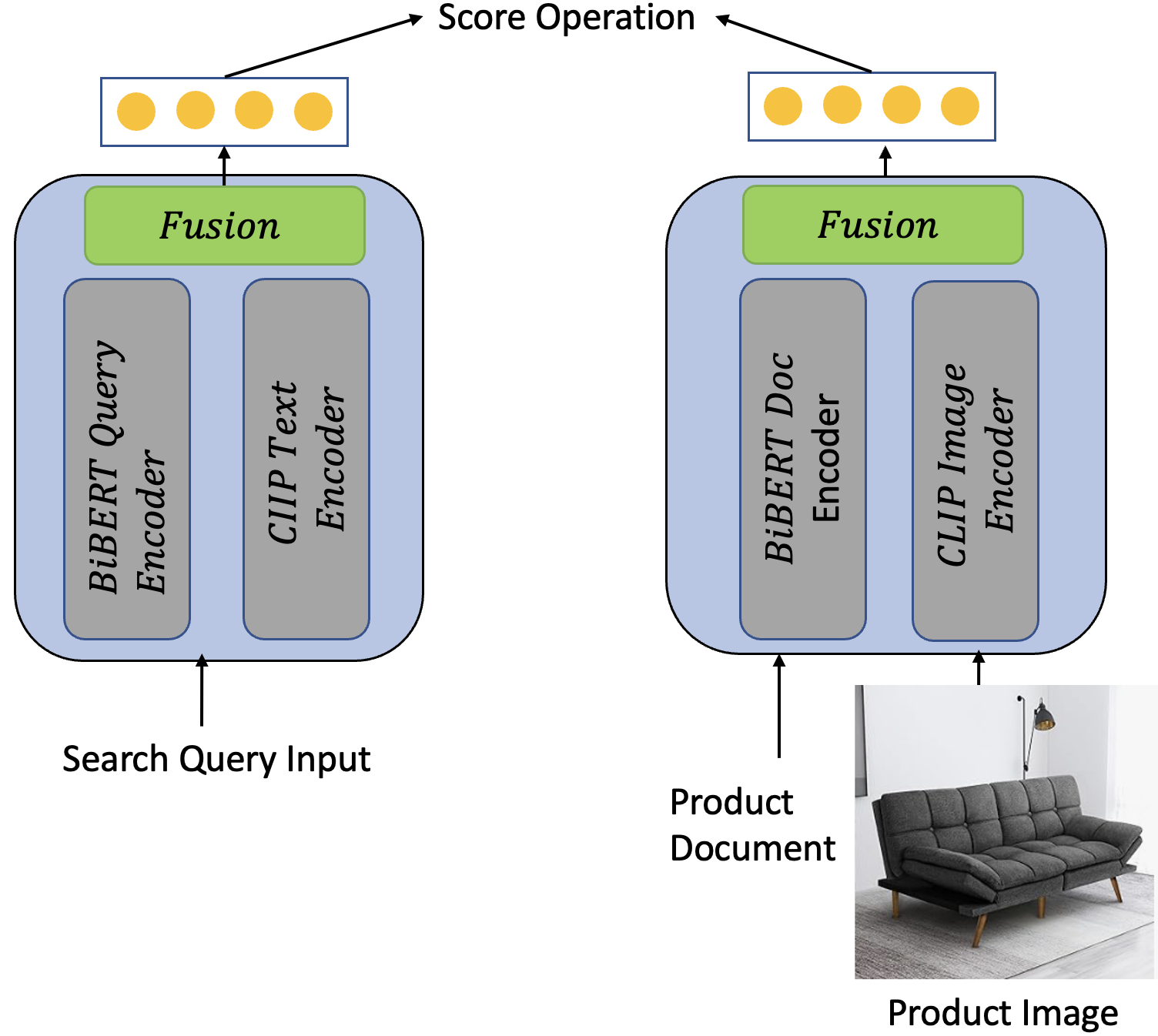
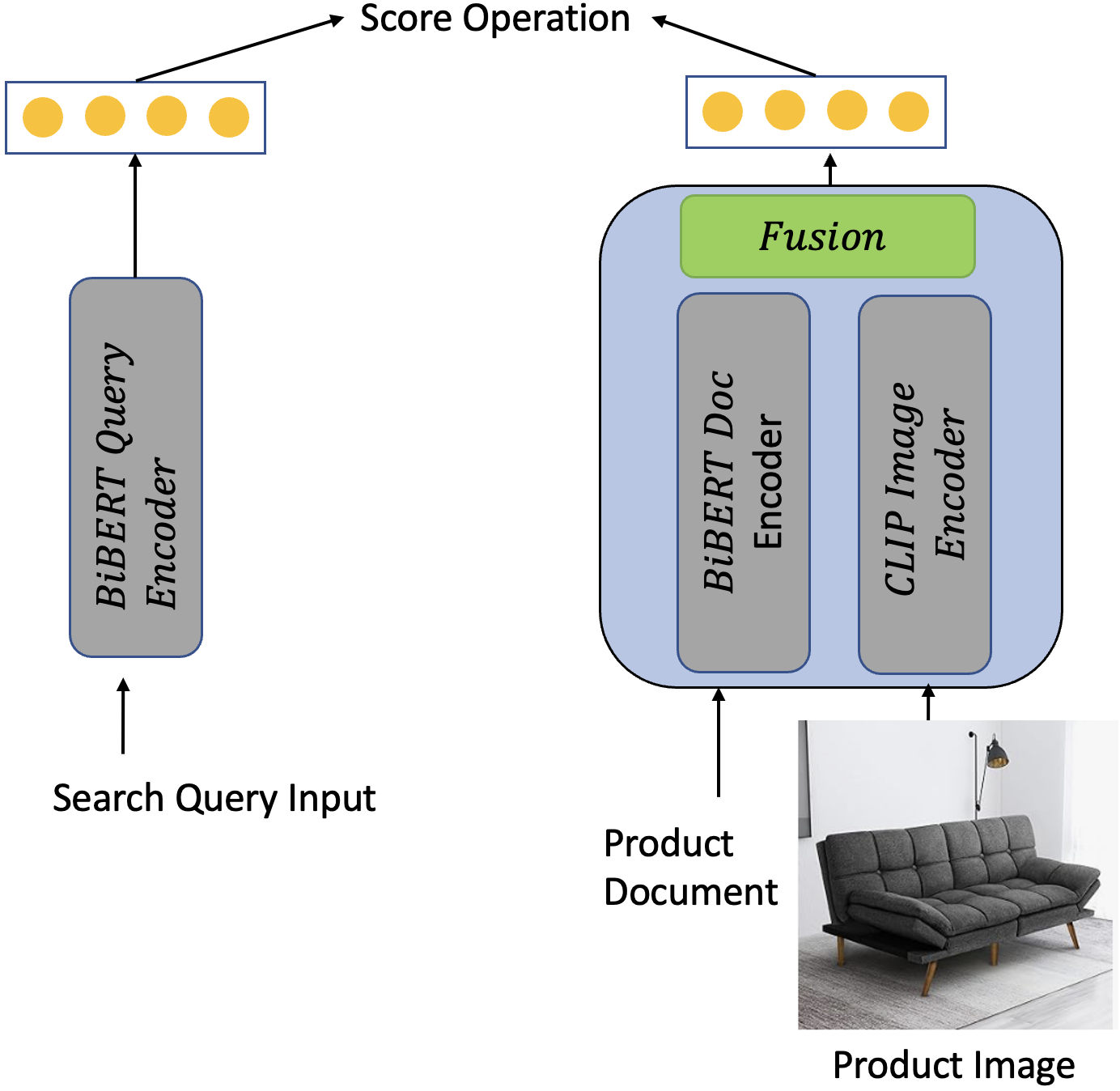
Figure: Example of the 3-tower and 4-tower architectures for multimodal semantic retrieval (source: arXiv:2501.07365).
- Text Tower: Encodes product title/description with BERT.
- Image Tower: Encodes product image with CLIP ViT.
- Fusion Tower: Combines text and image embeddings (e.g., concatenation, MLP).
- Query Tower: Encodes user query (text) for retrieval.
The core idea is to map both product queries and catalog items into a shared multimodal embedding space. This is achieved by fusing deep representations of text and images, enabling semantic search and retrieval across modalities.
Key components:
- Text Encoder: Transformer (BERT) for product text.
- Image Encoder: Vision Transformer (CLIP) for product images.
- Fusion Module: Projects and fuses the two modalities into a single vector.
- Retrieval: Uses cosine similarity in embedding space for ranking.
Given:
- Query
$q$ - Product text
$p_\mathrm{text}$ - Product image
$p_\mathrm{img}$
We define embedding functions:
-
$f_\mathrm{text}(q)$ : maps the query to the embedding space -
$f_\mathrm{mm}(p_\mathrm{text}, p_\mathrm{img})$ : maps the product (with fused modalities) to the embedding space
The objective is to maximize similarity for true query-product pairs and minimize it for negatives, using the InfoNCE contrastive loss:
Where:
-
$\mathrm{sim}(\cdot, \cdot)$ is cosine similarity, -
$\tau$ is the temperature parameter, -
$N$ is the batch size.
git clone https://github.com/mayurbhangale/multimodal-retrieval.git
cd multimodal-retrieval
pip install -r requirements.txt
- Train
python train.py \
--csv https://raw.githubusercontent.com/luminati-io/eCommerce-dataset-samples/refs/heads/main/amazon-products.csv \
--epochs 2 --batch_size 8 --max_samples 2000
- Demo
python demo.py
Dong Liu & Esther Lopez Ramos (2024) / Amazon: Multimodal Semantic Retrieval for Product Search