A CLI text-to-speech tool using the Kokoro model, supporting multiple languages, voices (with blending), and various input formats including EPUB books and PDF documents.
- Multiple language and voice support
- Voice blending with customizable weights
- EPUB, PDF and TXT file input support
- Standard input (stdin) and
|piping from other programs - Streaming audio playback
- Split output into chapters
- Adjustable speech speed
- WAV and MP3 output formats
- Chapter merging capability
- Detailed debug output option
- GPU Support
Kokoro TTS is an open-source CLI tool that delivers high-quality text-to-speech right from your terminal. Think of it as your personal voice studio, capable of transforming any text into natural-sounding speech with minimal effort.
demo.mp4
Demo Audio (MP3) | Demo Audio (WAV)
- Add GPU support
- Add PDF support
- Add GUI
- Python 3.9-3.12 (Python 3.13+ is not currently supported)
The easiest way to install Kokoro TTS is from PyPI:
# Using uv (recommended)
uv tool install kokoro-tts
# Using pip
pip install kokoro-ttsAfter installation, you can run:
kokoro-tts --helpInstall directly from the repository:
# Using uv (recommended)
uv tool install git+https://github.com/nazdridoy/kokoro-tts
# Using pip
pip install git+https://github.com/nazdridoy/kokoro-tts- Clone the repository:
git clone https://github.com/nazdridoy/kokoro-tts.git
cd kokoro-tts- Install the package:
With uv (recommended):
uv venv
uv pip install -e .With pip:
python -m venv .venv
source .venv/bin/activate # On Windows: .venv\Scripts\activate
pip install -e .- Run the tool:
# If using uv
uv run kokoro-tts --help
# If using pip with activated venv
kokoro-tts --helpIf you prefer to run without installing:
- Clone the repository:
git clone https://github.com/nazdridoy/kokoro-tts.git
cd kokoro-tts- Install dependencies only:
With uv:
uv venv
uv syncWith pip:
python -m venv .venv
source .venv/bin/activate # On Windows: .venv\Scripts\activate
pip install -r requirements.txt- Run directly:
# With uv
uv run -m kokoro_tts --help
# With pip (venv activated)
python -m kokoro_tts --helpAfter installation, download the required model files to your working directory:
# Download voice data (bin format is preferred)
wget https://github.com/nazdridoy/kokoro-tts/releases/download/v1.0.0/voices-v1.0.bin
# Download the model
wget https://github.com/nazdridoy/kokoro-tts/releases/download/v1.0.0/kokoro-v1.0.onnxThe script requires
voices-v1.0.binandkokoro-v1.0.onnxto be present in the same directory where you run thekokoro-ttscommand.
| Category | Voices | Language Code |
|---|---|---|
| 🇺🇸 👩 | af_alloy, af_aoede, af_bella, af_heart, af_jessica, af_kore, af_nicole, af_nova, af_river, af_sarah, af_sky | en-us |
| 🇺🇸 👨 | am_adam, am_echo, am_eric, am_fenrir, am_liam, am_michael, am_onyx, am_puck | en-us |
| 🇬🇧 | bf_alice, bf_emma, bf_isabella, bf_lily, bm_daniel, bm_fable, bm_george, bm_lewis | en-gb |
| 🇫🇷 | ff_siwis | fr-fr |
| 🇮🇹 | if_sara, im_nicola | it |
| 🇯🇵 | jf_alpha, jf_gongitsune, jf_nezumi, jf_tebukuro, jm_kumo | ja |
| 🇨🇳 | zf_xiaobei, zf_xiaoni, zf_xiaoxiao, zf_xiaoyi, zm_yunjian, zm_yunxi, zm_yunxia, zm_yunyang | cmn |
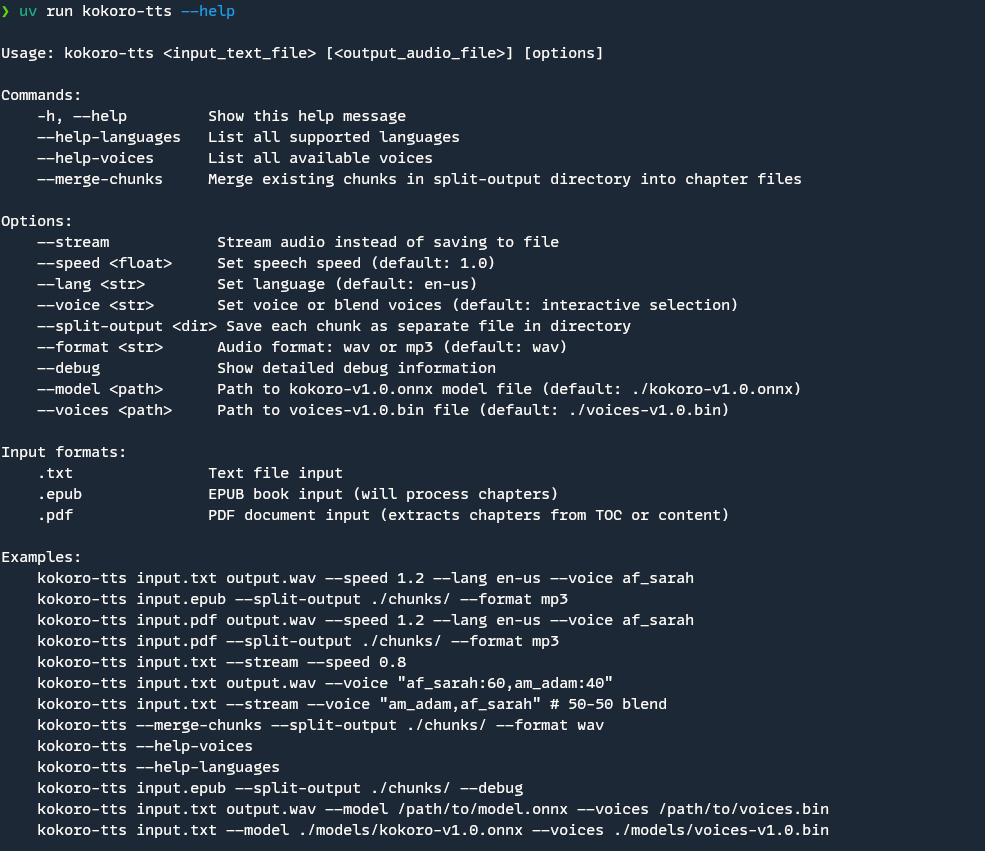
kokoro-tts <input_text_file> [<output_audio_file>] [options]Note
- If you installed via Method 1 (PyPI) or Method 2 (git install), use
kokoro-ttsdirectly - If you installed via Method 3 (local install), use
uv run kokoro-ttsor activate your virtual environment first - If you're using Method 4 (no install), use
uv run -m kokoro_ttsorpython -m kokoro_ttswith activated venv
-h, --help: Show help message--help-languages: List supported languages--help-voices: List available voices--merge-chunks: Merge existing chunks into chapter files
--stream: Stream audio instead of saving to file--speed <float>: Set speech speed (default: 1.0)--lang <str>: Set language (default: en-us)--voice <str>: Set voice or blend voices (default: interactive selection)- Single voice: Use voice name (e.g., "af_sarah")
- Blended voices: Use "voice1:weight,voice2:weight" format
--split-output <dir>: Save each chunk as separate file in directory--format <str>: Audio format: wav or mp3 (default: wav)--debug: Show detailed debug information during processing
.txt: Text file input.epub: EPUB book input (will process chapters).pdf: PDF document input (extracts chapters from TOC or content)-or/dev/stdin(Linux/macOS) orCONIN$(Windows): Standard input (stdin)
# Basic usage with output file
kokoro-tts input.txt output.wav --speed 1.2 --lang en-us --voice af_sarah
# Read from standard input (stdin)
echo "Hello World" | kokoro-tts - --stream
cat input.txt | kokoro-tts - output.wav
# Cross-platform stdin support:
# Linux/macOS: echo "text" | kokoro-tts - --stream
# Windows: echo "text" | kokoro-tts - --stream
# All platforms also support: kokoro-tts /dev/stdin --stream (Linux/macOS) or kokoro-tts CONIN$ --stream (Windows)
# Use voice blending (60-40 mix)
kokoro-tts input.txt output.wav --voice "af_sarah:60,am_adam:40"
# Use equal voice blend (50-50)
kokoro-tts input.txt --stream --voice "am_adam,af_sarah"
# Process EPUB and split into chunks
kokoro-tts input.epub --split-output ./chunks/ --format mp3
# Stream audio directly
kokoro-tts input.txt --stream --speed 0.8
# Merge existing chunks
kokoro-tts --merge-chunks --split-output ./chunks/ --format wav
# Process EPUB with detailed debug output
kokoro-tts input.epub --split-output ./chunks/ --debug
# Process PDF and split into chapters
kokoro-tts input.pdf --split-output ./chunks/ --format mp3
# List available voices
kokoro-tts --help-voices
# List supported languages
kokoro-tts --help-languagesTip
If you're using Method 3, replace kokoro-tts with uv run kokoro-tts in the examples above.
If you're using Method 4, replace kokoro-tts with uv run -m kokoro_tts or python -m kokoro_tts in the examples above.
- Automatically extracts chapters from EPUB files
- Preserves chapter titles and structure
- Creates organized output for each chapter
- Detailed debug output available for troubleshooting
- Chunks long text into manageable segments
- Supports streaming for immediate playback
- Voice blending with customizable mix ratios
- Progress indicators for long processes
- Handles interruptions gracefully
- Single file output
- Split output with chapter organization
- Chunk merging capability
- Multiple audio format support
- Shows detailed information about file processing
- Displays NCX parsing details for EPUB files
- Lists all found chapters and their metadata
- Helps troubleshoot processing issues
- Text file input (.txt)
- EPUB book input (.epub)
- Standard input (stdin)
- Supports piping from other programs
This is a personal project. But if you want to contribute, please feel free to submit a Pull Request.
This project is licensed under the MIT License. See the LICENSE file for details.